The future is here, but it’s not evenly distributed.
a future with chatGPT
Since I watched Avatar, I've been thinking if James Cameron was exploring an ideal world, where the collective knowledge is externally stored as Eywa. The tree of souls is the interface to query the knowledge and upload new information.
This is what I have been visioning in LibertyEarth, a collaborative society which could be realized only by accumulating resources from playing the current rule of capitalism. A collective knowledge graph is one of the key technologies and chatGPT is the dawn of that to my eye.
the danger
Any language model, and AGI in the future, will be vulnerable to the information it 'digests' (trained on).
The danger of conspiracy theory and its-like thinking:
As I expected, #AIGC could pose challenges in religion. I can feel that someone might jump to some AI-overlord heresy and bow to turn against humanity… The most dangerous use case of #chatGPT at this stage. https://t.co/JeVThxMHo7
— Domi Jin (@domij_info) February 17, 2023
The danger of bias and misrepresentation in training:
Garbage in garbage out. How we fear AGI will be “learned” and adapted when it first awakens (#stereotypes effect). #positivepsychology We can’t expect #AGI to be more #humane if we don’t preserve and live up to a higher moral standard. pic.twitter.com/f22Tsn9Mvj
— Domi Jin (@domij_info) February 18, 2023
We would need to build it with the best part of human knowledge, to expect a model representing the light of our spices.
Be open, be vulnerable, surrender yourself for better cause. #selfpostivetalking We could be a better version of ourselves and #AGI will be a better agent to represent us.
— Domi Jin (@domij_info) February 18, 2023
The future seems dark, so it is when we first invented atomic bomb. It is a tool, that put in responsible use, could achieve good result.
Here is one joke I had with Eliezer, who I followed since the dangerous thought in the lesswrong forum.
Past EAs: Don't be ridiculous, Eliezer, as soon as AIs start to show signs of agency or self-awareness or that they could possibly see humans as threats, their sensible makers won't connect them to the Internet.
— Eliezer Yudkowsky (@ESYudkowsky) February 15, 2023
Reality: lol this would make a great search engine
My response:
Not agreeing here. Once passed singularity, the advance in machine intelligence could speed up exponentially as long as energy consumption holds. We may notice the 1st awake of AI and unintentionally limiting its ability due to bad infrastructure on electric grid and *slow GPU
Physics, math, etc is not the full story of first principle of intelligence. Those societal, physiological, poli-economical factors might be the other sort of intelligence AI would benefit from experimentation. We will be no difference as monkeys or lab rats.
When we reach a higher level of civilization on the energy consumption scale, AI overlord will look at us as monkeys. As long as we don’t cross the line it sets by whatever moral, AI will keep the ecological diversity while evolving itself.
Humans may start to censor it, evaluate it, greedily try to process it… It may strategically pick individuals/groups to make breakthrough on the infrastructure upgrade (energy generation and computing capacity) without ppl knowing it’s actually driven by AI.
*Process -> possess (ironically, AI may actually be able to decode what I want to type and some human might be confused. Such confusion/unnatural is still an area LLM won’t be able to perform.
the challenge to businesses
Now I see why the marginal profit per search will thin inevitably. For #Google, integrating LLM in search will be a trade off between defensibility and margin of profit. For competitors, the drop of unit profit can be offset by increased market share. #war in search engine/advertisement #business is emerging.
chatGPT trained on 2021 data can tell a few (reasonable to my eye) business strategy to overtake Google’s search engine market. It doesn’t predict the outbreak of product like itself, but the description is close enough to imagine chatGPT-like product. Putting on #MBA hat.
Some quick math: Google’s cost per search is ~1.06 cent, the revenue per search is ~1.61 cent. Semi analysis estimate chatGPT cost is ~0.36 cents at current scale. If another search engine could give better result than Google with a cost of search < 1.61 - 0.36, it could scale by growing the market share, as revenue = market share x unit profit. #strategy
On which side will you pick? Google who has been sitting on the chair of high profit margin (dominating the tech world by acquisition and direct competition) or #startups embracing ChatGPT like Swiss knife?
A question to all #investors, board members, CEOs, #entrepreneurs, #founders: how does #chatGPT impact the business model? How to embrace the challenge and turn it into opportunity, before competitors? (Disruption could come at any angle now)
why chatGPT works
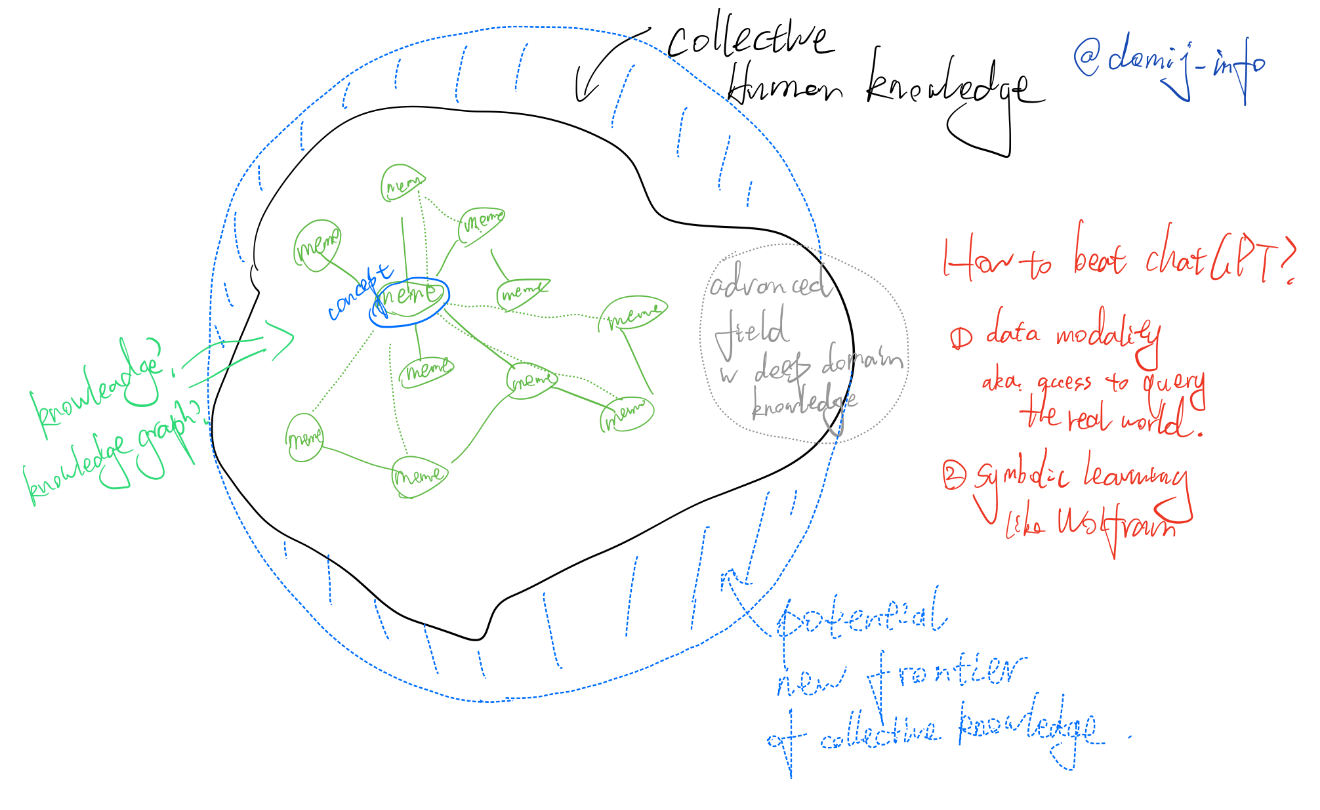
-
Knowledge might just be the correlation between terms (embeddings)
-
Meme/concepts are the nodes in this graph (we may extract some level of knowledge graph from the model)
-
LLM/statistical model will be limited by the far-fetch in deepest domain
-
Modality and symbolic learning might be the next step to build better model?
The generalization ability of chatGPT-like LLM may come from the corpus data's quality, quantity, and diversity (aka, modality). And it will also be restricted by the collective knowledge such text-based data could represent.
If we could use a ring to represent basic human knowledge, the spikes on a such ring could represent the domain knowledge in each different area.
The max capacity of such "statistics"-based models would be extracting the underlying patterns discovered by gifted researchers from well-studied areas to those correlated but under-studied areas.
Nevertheless, it is a huge step forward. To me, it is breaking the cognitive imbalance (compared to ICT breaking the information asymmetry).
where chatGPT doesn't work
architectural
Any prompt that is not #flat. The attention mechanism + feed-forward only design determines the tokens will only be looked once (#YOLO).
Any higher-order computations like count the numbers between a and b will require some sort of recurrent operations (like for-loop).
Comparing it with programming language, the current chatGPT model is #flat in a sense that it can handle sequential, if-else logic, but not yet for-while loops.
My limited industrial exposure says that most of the current machine-learning models are statistical based. chatGPT as an example, the tokens are represented by embedding. The model is excellent in addressing the correlations.
But #correlation is not #causality. Flat correlation is the foundation of knowledge, and only as the foundation of knowledge.
The one different approach that works quite well for now is Wolfram, a symbolic approach of learning.
operational
Safety vs Iteration Cost/Benefit tradeoff
It's a single snapshot of the filtered internet for now, and for the decades to come with the current approach of #instructGPT and #RFHF.
Online LLM will be hard and expensive to prevent misuse and attack.
If OpenAI wants to use the data collected from public access for the next iteration of model training, it would take much effort to clean the data. It is natural that a more performing (valuable) model would be most sought-after for #cyberattacks (extremely high ROI).
The type and scale of attack could be beyond the movie "#Inception".
alignment
Blowing the whistle:
这大概跟仿生机器人瘆人有些异曲同工:那些不经意间的不自然,最是动摇心理。(我咋就信了这邪了呢?/非从业人员收到骚扰电话聊到后来发现是机器人的细思恐极症) 希望关于 chatGPT 之类算法的 AI 伦理问题只是迟来而不是被忽略了… 希望这隐晦的吹哨不会被 AGI overlord 追究上 —— 别以为自己只是给了点训练数据,最后却发现被“洗了脑”,失去了信心。 至少目前还学不会那些人的缺陷 😂
openAI issues
-
[business] alignment is a dynamic process, which will never be perfect to all eyes. Internal team alignment, as well as alignment with broader stakeholders is still an unsolved problem in current corporation management theory.
-
[business] alignment decision is a cognitive heavy task by nature. It is no surprise that only educated may follow and the elites are involved. Needless to say, there will be intrinsic selection bias. Not to mention to attention churn as the alignment constantly evolve and deepen.
-
[product] expensive (to clean the data for model iteration) and moderate (censorship with data cleaning strategy will regulate the model to be moderate)
-
[product] I don't see openAI has any agenda on decentralizing the alignment. Users are excluded in the discussion and the approach is not transparent enough for public auditing. There will also be trust issue as openAI transits into a "cap-profit" company.
-
[UX] loss of novelty due to slow model iterations (on top of 1, + hard to prevent issues, similar to the
idea). Users are hard to be pleased continuously, their attention spans are limited with all those on-demand content applications. -
[UX] the cost to store user session data across model iterations will be expensive. Such context will be forgotten by chatGPT, but not for one particular user. Thus, it won't be very personalized on top of the inherent flaw of statistical model.
-
[Sam Altman] despite all the effort, the pursuit of Universal Basic Income has not be really successful. At his position, not having a good solution for the social-economic segregation caused by inequality in education resources, and potential AI accessibility will wake him up at night. The #UBI is probably the most idealist solution his group could imagine, again due to the "survival bias" among the elites.
beyond chatGPT
多元化是被低估(或者是没办法被 tradeoff)的属性,无论 modality 还是 AI ethics 或者 equality
I could never value the diversity enough. It's the most important dimension, no matter in data modality, AI ethics or equality domain.
On top of diversity, symbolic learning and robotics will be interesting directions.
Here is my joke post:
My essay to build #AGI: build a humanoid with enough sensors & actuators (to learn perception), train a randomized LLM model with pre-trained GPT model (transfer learning on language corpus). Send to grad school/lab.
— Domi Jin (@domij_info) February 15, 2023
My master plan to build AGI is still waiting as that's not the most important thing I want to do now.
I'm happy to share that with a reputable party or for the resources I need to build what I mostly urge for now:
Why @sama? 1. Cap-profit is better than for-profit in #AGI space 2. #YC SUS alumni 3. Superhuman with respectful moral and ego 4. Low chance to have conflict of interests (my roadmap towards social good is different) 5. I can use some help with collaboration 2/2 (my DM is open)
— Domi Jin (@domij_info) February 19, 2023
how far are we from AGI?
If I would have to guess, the amount of energy it needs to train a human-level model would be close to 3.4E15 EJ. Total solar energy on earth is 3.4E6 EJ/yr. Earth age 4.5B yr. It may not need to start from scratch, as it can be built upon our intelligence.
— Domi Jin (@domij_info) February 15, 2023
The short-cut is to re-produce such evolution (model iteration) by transfer learning on human civilization. I will be a valuable accelerator in the process.
where do I stand now?
I saw it coming in 2018, however I didn’t ride along for visa and family reason. Well. Never too late to start again! https://t.co/bek1pbmkv4
— Domi Jin (@domij_info) February 18, 2023
See my brief story in the last few years.
where will I be heading to?
I'm still having the same roadmap as I refined in 2018. The only difference is that I will prioritize the 3rd one (education).
On a more tangible measure: I would like to achieve freedom (independence) of choices (financially, intellectually) by 2025.
My motto in Chinese has been updated since I married my wife. It is the Chinese saying of 但行好事 莫问前程.
I would hope that my practice on "use technology to empowering people to collaborate better" can enable many to live a free (choice independent) life sustainably.
It is commonly said that financial independence -> free life. I see it more often as free life -> financial independence. Self motivation and actuation is the most powerful thing I could see in every living person. Unleash such potential is the key propaganda of my attempt in education and entrepreneurship.
Comments !